new
Health Score
Duplicity
The goal of the Duplicity Project is to facilitate an uninterrupted flow of data from users who are connected to multiple data sources. This capability empowers our clients to make informed decisions based on their users' data, assured of its superior quality. The project's architecture is built around critical elements such as data prioritization, event generation, summary creation, and the cleansing of data within these summaries. This approach ensures that our clients have access to the most relevant and accurate information, enabling them to take proactive and effective actions based on user data.
Data Prioritization
Rook's method for managing multiple data sources begins with the crucial step of data prioritization. The accompanying table illustrates our ranking of data sources across our 3 health pillars. This ranking is based on the quality and comprehensiveness of the data each source provides in relation to the specific metrics constituting each health pillar.
The table's arrangement, from top to bottom, reveals a clear preference hierarchy. Data sources directly linked to biometric devices take precedence over health kits. Additionally, the hierarchy within these data sources is evident. For instance, Garmin is the top choice for data related to Physical Health, whereas Oura is the foremost source for sleep-related data.

There are also complementary rules for prioritizing and creating more robust data structures. These are two:
Non-Null Value
The new value, regardless of priority, has a non-null value
- If the data source with the highest priority returns a variable with a Null value and another data source returns the same variable with a value of 10, the latter value from the data source with the lowest priority will be used.
- If the data source with the highest priority returns a variable with a value of 0 and another data source returns the same variable with a value of 10, the latter value from the data source with the lowest priority will be used.
Higher Value
The new value has a higher value, regardless of priority. This rule is only available or applied to a few variables.
{
'calories_intake_number',
'steps_number',
'accumulated_steps_int',
'calories_net_intake_kilocalories',
'calories_expenditure_kilocalories',
'calories_net_active_kilocalories',
'calories_basal_metabolic_rate_kilocalories',
'activity_duration_seconds',
'active_seconds',
'rest_seconds',
'low_intensity_seconds',
'moderate_intensity_seconds',
'vigorous_intensity_seconds',
'inactivity_seconds',
'steps_per_day_number',
'active_steps_per_day_number',
'calories_intake_number',
}
Event Generation
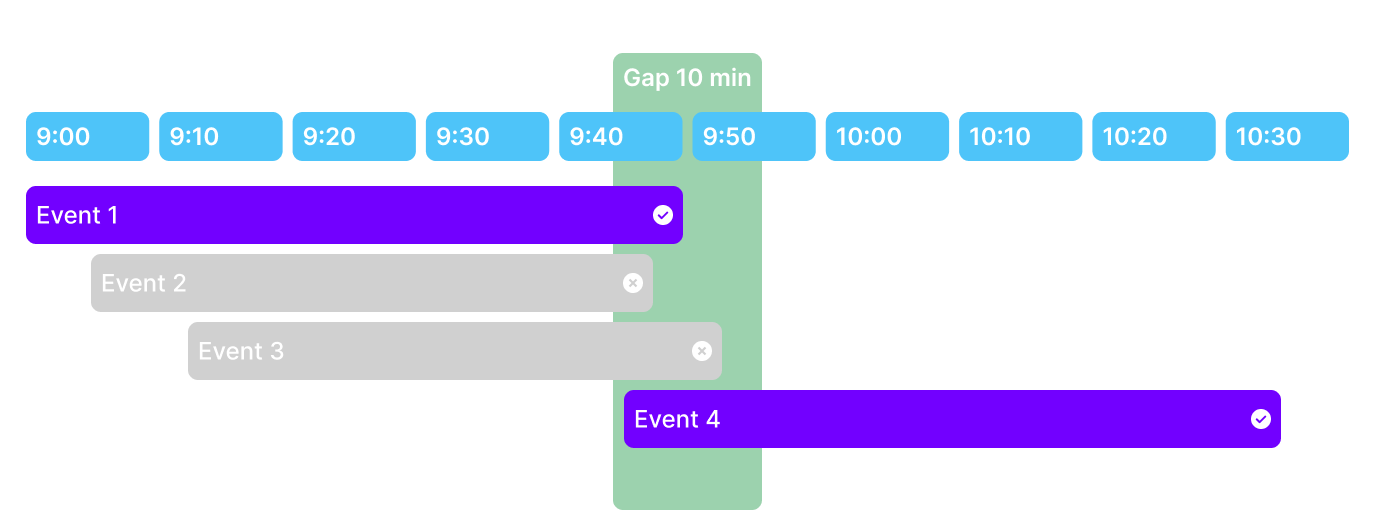
ROOK provides refined, processed data from our health categories in the form of events and summaries. The Data Duplicity feature in ROOK has a defined method for managing duplicate data points related to a particular event. Priority is assigned to the first recorded event. Later events from different data sources, occurring within a close time range, are disregarded. We permit a time frame of plus or minus 10 minutes to capture a maximum of two successive events within this interval. In this procedure, priority is given to data sources that are directly connected to wearable devices over health kits and SDK extractions.
Summary Generation
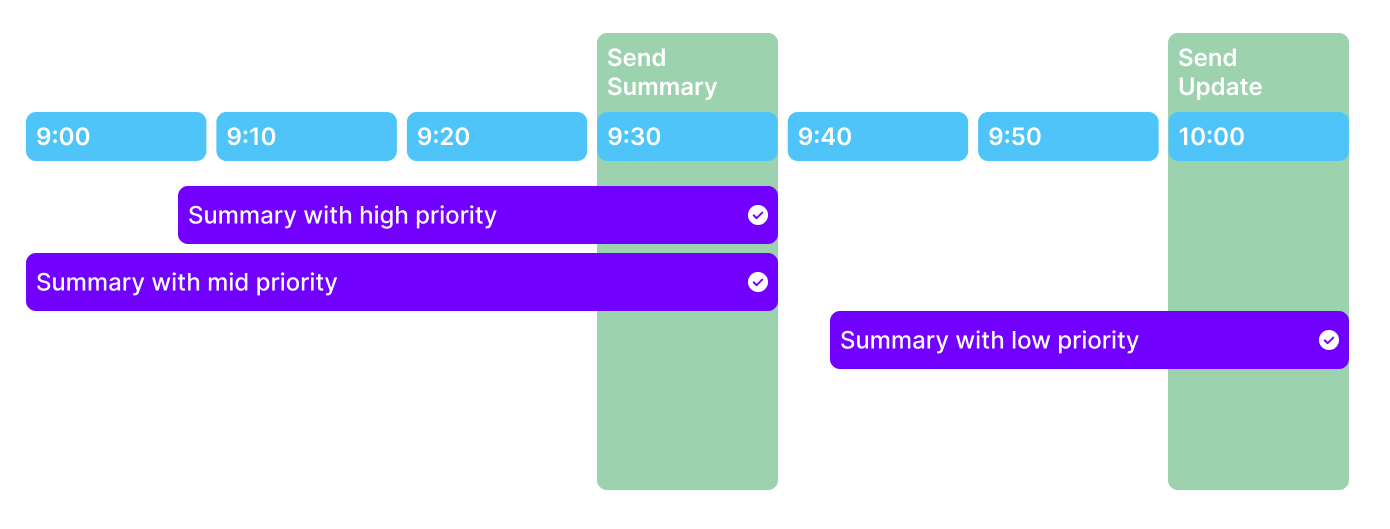
The creation of summaries relies on the data available at the time of calculation. Initially, a summary is formed using the first data source received. This summary is then enhanced with extra data from other sources. Once the initial summary is dispatched, there is a 15-minute interval before an updated summary, incorporating any new data, is sent. These subsequent summaries are marked as updated versions.
Combine data into summaries
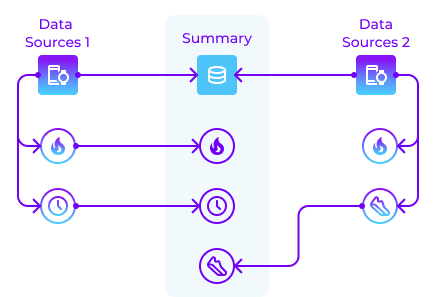
When confronted with two distinct summaries originating from the same date, both are attributed to the corresponding day. Herein, the process of data cleaning is invoked: data originating from the source deemed most relevant within the specific pillar takes precedence. This primary data is then supplemented with additional information sourced from other sources, in accordance with their position in the prioritization table. This meticulous methodology is designed to furnish comprehensive information without manipulating the original data, thereby ensuring accuracy and fidelity to the primary data sources.
Frequent Questions
What is the primary objective of the Duplicity project?
The fundamental aim of the Duplicity project revolves around interconnecting two or more data sources to mutually enhance their capacities. This comprehensive integration endeavors to furnish our clients and users with a more enriched and thorough oversight of the information provided.
How are data source priorities established within the Duplicity project?
Prioritizing data sources hinges upon specific pillars defined within the framework of ROOK. We rely on a ranking table that assesses the scientific substantiation endorsing each data source's specialization within a given pillar. For instance, Garmin holds the highest priority in physical health, while Oura assumes precedence in sleep health.
How is the aggregation of summaries from multiple data sources managed?
Summaries initiate with data from the primary received source and are augmented with supplementary information from other sources based on their priority levels. A 15-minute interval ensues between the receipt of the initial summary and any subsequent summaries before disseminating consolidated information to the client.
Is there a process to ensure data integrity and precision in the summaries?
Indeed, a meticulous data cleaning strategy is implemented. When two summaries from different sources with identical dates are received, precedence is granted to information sourced from the most relevant data source concerning the specific pillar. This information is then complemented by data from other sources based on their placement in the prioritization table.
What transpires when summaries from distinct sources present conflicting data?
In cases where summaries from diverse sources present contradictory data but share the same date, the Duplicity project prioritizes information from the data source deemed more pertinent to the specific pillar. This data is amalgamated with additional insights from other sources based on their standing in the prioritization table, aiming to provide a comprehensive and coherent perspective without altering the original data.
What unfolds if multiple summaries arrive post the initial delivery to the client?
Upon reception of additional summaries subsequent to the initial delivery to the client, an update notification is dispatched. The client then has the discretion to review and implement this update, facilitating the generation of an updated version of the summary. This process keeps the client informed of any supplemental information received post the initial dissemination.
What occurs in the scenario of receiving multiple events from various data sources?
A lucid protocol is established: precedence is afforded to the initial recorded event, disregarding subsequent events from other sources sharing a similar timestamp. A window of +/- 10 minutes is permitted for continuous events, allowing the recording of up to two events if they fall within this timeframe.